
Published Jun 1, 2026
Hermes Agent vs. OpenClaw: A technical look at convergent evolution in agentic memory and orchestration
The recent Hermes Agent papers have sparked productive discussion around persistent memory, tool-use abstraction, and reflection loops in autonomous agents.
Rather than adding to the hype, I want to compare Hermes’ proposed architecture with an implementation that has been running in production for over a year: OpenClaw.
The goal is not to claim priority, but to show where the patterns converge—and where OpenClaw already solved several of the same engineering challenges.
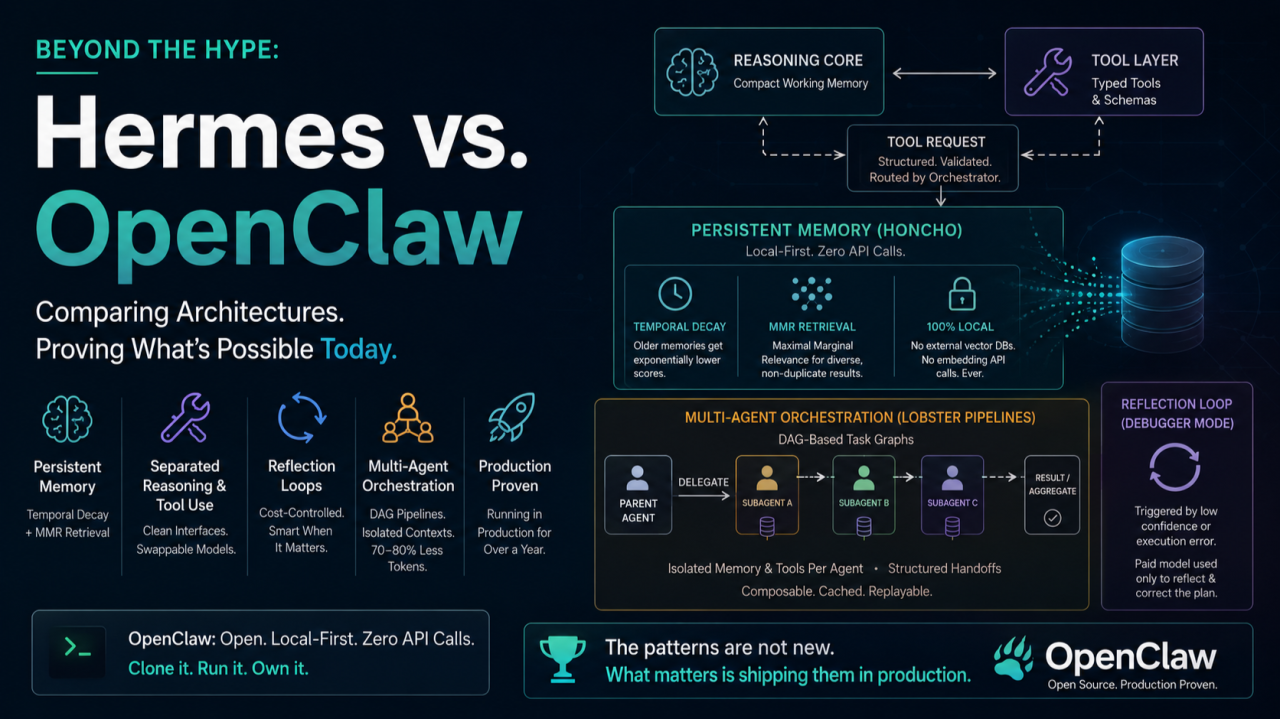
Memory architecture
Hermes proposes cross-session persistent memory with vector retrieval and decay mechanisms.
OpenClaw implements this using Honcho as a local-first, programmable memory layer. Key technical choices:
- Temporal decay: older memories receive exponentially lower retrieval scores. This prevents stale context from dominating the working memory.
- MMR (Maximal Marginal Relevance): the retriever balances similarity to the current query with diversity among returned memories. No duplicate near-identical passages.
- Zero API calls: the entire memory system runs locally—no round trips to paid vector databases or external embedding services.
Reasoning vs. tool use
Hermes describes a clean separation between the agent’s reasoning core and its tool-calling surface.
OpenClaw has had this separation since its first release:
- The reasoning loop operates on a compact “working memory” view.
- Tools are defined as modular, typed functions with explicit schemas.
- The agent never calls tools directly; it emits a structured “tool request” that the orchestrator routes and validates.
This allows swapping models (e.g., from a small local model to GPT-4) without changing the tool interface—a pattern that keeps inference cheap for 95% of steps.
Reflection loops
Hermes introduces a “reflection loop” for self-correction.
OpenClaw implements this as a debugger-only constraint:
- The agent runs primarily on small, fast models (Ollama, llama.cpp).
- A paid model (OpenAI, Anthropic) is only invoked when the agent hits a confidence threshold or an execution error—and only to reflect on the failure and produce a corrected plan.
- This keeps reflection loops from becoming a cost multiplier.
Multi-agent orchestration
Hermes proposes subagent delegation with isolated contexts.
OpenClaw uses Lobster pipelines—DAG-based task graphs:
- Each subagent runs in its own memory and tool context.
- Parent agent delegates via a structured handoff (passing only the relevant slice of state).
- Pipelines can be composed, cached, and replayed for zero-cost failure recovery.
In production tests, this reduces token consumption by 70-80% on multi-step tasks compared to a single agent handling everything.
Where Hermes is genuinely new
To be fair, Hermes formalizes the deployment and lifecycle management of such agents (versioning, rollback, A/B testing of memory parameters). OpenClaw currently lacks that polish—it’s a developer-first toolkit, not a managed platform.
That’s a useful direction for the whole field.
Bottom line
If you are building an agent today, you don’t need to wait for a closed-source implementation of Hermes.
The core patterns—persistent memory with temporal decay, MMR retrieval, separated reasoning/tool layers, cost-controlled reflection loops, and DAG-based subagent orchestration—are already implemented in OpenClaw, with full configuration files and examples available.
You can clone it, run it on a laptop, and start modifying the architecture in an afternoon.
The article that documents all of this is here: Building OpenClaw on a Zero-Dollar Budget: Hybrid Multi-Agent Memory with Temporal Decay & MMR
Let’s keep the conversation technical. Which part of this architecture would you like to dive deeper on?